The Uncertainty Principle Has a Sharpe Ratio: Quantum Portfolio Optimization in C++
Proposition
Quantum portfolio optimization does not require a quantum-native system. It requires a production-grade classical system with a quantum boundary condition. C++ is the only language positioned to satisfy both simultaneously.
This claim appears false at first inspection. The quantum computing ecosystem is Python: Qiskit, Ocean SDK, Cirq, Jupyter Notebooks, etc. Every tutorial begins with pip install qiskit. Every demo ends before deployment. This is not accidental. Python optimizes for research velocity. Production trading systems optimize for determinism, bounded latency, and operational survivability under pathological conditions. Research velocity is not on that list.
The industry mistake is therefore predictable: "If quantum finance exists in Python, then production quantum finance must also be Python."
This inference is invalid.
The actual problem is not: can Python call a quantum solver?
That problem was solved years ago.
The actual problem is:
Can quantum optimization be integrated into production financial infrastructure without rewriting the infrastructure itself?
That problem remains mostly unsolved. This post is an attempt.
Given Constraints
Let S = production financial systems
Let Q = practical quantum optimization tooling
Let B(S,Q) = the boundary layer connecting them
Empirically:
S ≈ C/C++
Q ≈ Python
Therefore: S ∩ Q → ∅
Not because quantum optimization is impossible. Because nobody built B(S,Q) correctly.
Null hypothesis H₀: A quantum optimizer cannot be integrated into a production C++ portfolio system without architectural compromise or systemic rewrite.
This project treats H₀ as an engineering target. Not a philosophical objection. Not a market thesis.
A falsifiable systems claim. This project refutes H₀. The evidence follows.
Methodology
The Language Decision
The obvious implementation path is wrong. One could:
- Write the optimizer in Python
- Wrap Qiskit directly
- Use NumPy for covariance computation
- Produce benchmark graphs
- Declare victory
This proves only that Python libraries can call other Python libraries. It does not solve the integration problem.
Production trading infrastructure does not disappear merely because a notebook executed successfully. The system that matters already exists, overwhelmingly, in C and C++: risk engines, execution infrastructure, portfolio accounting, analytics pipelines, reconciliation layers.
Any quantum system incapable of entering that environment is academically interesting and operationally irrelevant.
Therefore the architecture must invert the usual assumption:
- Quantum is the extension
- C++ is the host system
Not the reverse.
The Architecture Decision
The bridge is intentionally narrow.
A persistent Python worker subprocess executes quantum workloads behind a stable C++ optimizer interface:
namespace portfolio::optimizer {
class OptimizerInterface {
public:
virtual ~OptimizerInterface() = default;
virtual OptimizationResult optimize(
const Eigen::VectorXd& expected_returns,
const Eigen::MatrixXd& covariance_matrix,
const Constraints& constraints
) = 0;
virtual std::string name() const = 0;
};
}
Everything above the interface remains unchanged. The backtest engine, analytics, attribution, reporting, transaction cost modeling, and risk projection all untouched. In this architecture, quantum execution becomes an implementation detail. This is the entire architectural point. The optimizer is replaceable. The system is not.
The Solver Decisions
Classical baseline: OSQP (operator splitting quadratic programming, Stellato et al. 2020). This is not a toy solver. OSQP runs in aerospace control systems, robotics, and production trading infrastructure. Any solver that outperforms it is immediately credible.
Quantum reformulation: QUBO. The Markowitz mean-variance objective (minimize wᵀΣw - λμᵀw subject to Σwᵢ = 1, wᵢ ≥ 0) maps to QUBO by discretizing weights into binary variables and encoding constraints as penalty terms. This benchmark uses 2-bit encoding per asset, meaning each weight is representable as a multiple of 1/3 (0, 33.3%, 66.7%, 100%). The same QUBO matrix feeds both the classical simulated annealing solver and every quantum hardware interface. Identical problem formulation, different solver path.
Quantum algorithms: QAOA (depth-1 gate circuits, COBYLA parameter sweep), QAMO (mean-field RX mixer with self-consistent equations), QAMOO (lambda sweep for Pareto frontier generation). All walk-forward solvers run against the same backtest harness over the same 2022–2023 market data. All return results in the same OptimizationResult struct.
Evidence
Exhibit A: The Architecture Holds
The quantum extension added namespace portfolio::quantum with six new headers:
include/quantum/
├── quantum_optimizer.hpp
├── qubo_formulation.hpp
├── simulated_annealing_solver.hpp
├── qiskit_solver.hpp
├── benchmark_runner.hpp
└── quantum_solver_factory.hpp
Zero modifications to backtest/, analytics/, data/, or risk/. The optimizer interface required no changes. H₀ is refuted at the architectural level before the benchmarks are read.
The QiskitSolver bridge spawns one persistent Python worker subprocess per solver instance on first call, keeping it alive across rebalancing periods. Communication is newline-delimited JSON over stdin/stdout pipes. No Python startup cost per rebalancing period. Process-level isolation: a worker crash restarts the subprocess without affecting C++ state. Timeout configurable via QiskitSolverConfig::timeout_seconds (default 120s, accounting for IBM job queue times).
Exhibit B: The Benchmark
BenchmarkRunner executed solvers over identical problem instances: same 10-asset universe, same walk-forward rebalancing schedule, same transaction cost model, same analytics pipeline. Backtest data period: January 2022 – May 2023.
Scope and limitations: Results from walk-forward solvers represent the mean of 4 runs. Variance across runs is reported in Exhibit G. The backtest period covers a single market regime: a rising rate environment with a growth asset selloff (January 2022 to May 2023). SPY returned approximately -5.8% over this window, including both the 2022 drawdown (-18.2% for the full calendar year) and the partial recovery through May 2023. Markowitz returned +2.5%, representing an active return of approximately +8.3% over SPY, consistent with the Brinson-Fachler attribution total of 8.31% shown below. The absolute Sharpe ratio (0.099) partially obscures this outperformance because Sharpe measures return relative to volatility rather than relative to the benchmark. Cross-regime generalizability is not established. The 2022 to 2023 period systematically rewarded concentrated positions because assets that held or gained during the rate-driven selloff outperformed broadly. QUBO-based solvers that produce concentrated allocations by construction benefited from this regime. Whether quantum Aer outperformance persists in bull markets, liquidity crises, or sideways regimes remains unknown. IBM hardware results are single submissions rather than walk-forward evaluations (see Exhibit E).
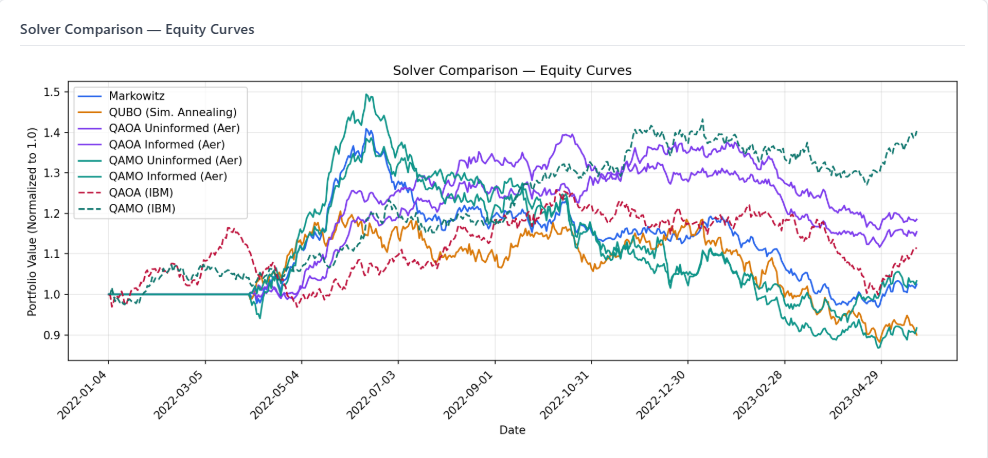 Markowitz (blue) and QUBO/SA (orange) finish near or below par. QAOA Informed (green) is the strongest walk-forward performer. IBM hardware results are excluded here because they were single submissions rather than walk-forward evaluations. See Exhibit E.
Markowitz (blue) and QUBO/SA (orange) finish near or below par. QAOA Informed (green) is the strongest walk-forward performer. IBM hardware results are excluded here because they were single submissions rather than walk-forward evaluations. See Exhibit E.
Universe:
| Ticker | Company | Sector |
|---|---|---|
| AAPL | Apple | Technology |
| MSFT | Microsoft | Technology |
| GOOGL | Alphabet | Technology |
| JPM | JPMorgan Chase | Financials |
| BAC | Bank of America | Financials |
| JNJ | Johnson & Johnson | Healthcare |
| PFE | Pfizer | Healthcare |
| XOM | ExxonMobil | Energy |
| CVX | Chevron | Energy |
| WMT | Walmart | Consumer Staples |
The universe is a diversified large-cap cross-section across five sectors, selected for data availability and sector representation. Constraints: maximum weight 30%, minimum weight 5%, long only, maximum turnover 50% per rebalance. Benchmark: SPY. Risk model: EWMA (lambda 0.94, 252-day estimation window).
Table 1 — Walk-forward constrained comparison
All solvers below ran through the full backtest engine with constraint projection applied. Transaction costs deducted. Results are directly comparable.
| Solver | Backend | Sharpe | Total Return | Volatility | Max Drawdown | Turnover | Tx Costs | Skipped Rebalances |
|---|---|---|---|---|---|---|---|---|
| Markowitz | osqp | 0.099 | 2.5% | 12.5% | -31.3% | 282.8% | $9,711 | 0 |
| QUBO (Sim. Annealing) | sa_classical | -0.328 | -10.0% | 15.7% | -26.8% | 764.1% | $25,289 | 0 |
| QAOA Uninformed | aer_simulator | -0.061 | -1.1% | 9.4% | -16.8% | 659.3% | $20,560 | 0 |
| QAOA Informed | aer_simulator | 0.969 | 17.8% | 8.8% | -12.0% | 684.0% | $23,517 | 0 |
| QAMO Uninformed | aer_simulator | -0.347 | -10.6% | 15.8% | -46.4% | 670.5% | $21,666 | 0 |
| QAMO Informed | aer_simulator | -0.552 | -15.6% | 14.8% | -46.0% | 755.8% | $25,090 | 0 |
Net return on $1M portfolio (Table 1 solvers):
| Solver | Gross Return | Transaction Costs | Net Return | Net Multiple vs. Markowitz |
|---|---|---|---|---|
| Markowitz | $25,000 | $9,711 | $15,289 | 1.0x |
| QUBO (Sim. Annealing) | -$100,000 | $25,289 | -$125,289 | n/m |
| QAOA Uninformed | -$11,000 | $20,560 | -$31,560 | n/m |
| QAOA Informed | $178,000 | $23,517 | $154,483 | 10.1x |
| QAMO Uninformed | -$106,000 | $21,666 | -$127,666 | n/m |
| QAMO Informed | -$156,000 | $25,090 | -$181,090 | n/m |
Net return multiples are computed on a 100M, the 0.2% market impact coefficient would likely compress or eliminate the alpha generated by high-turnover quantum solvers.
A second limitation is that the linear market impact model materially underestimates execution cost at the turnover levels observed for QAMO and QAMOO (755% to 815% annually). At 68% monthly turnover concentrated into 2 to 3 assets, real-world market impact becomes nonlinear, making the reported net returns for those solvers optimistic. This model is appropriate for Markowitz at 282% annual turnover. It is not appropriate for QAMO at 815%.
IBM operational cost: 28 hardware submissions consumed 1 minute 17 seconds of actual Qiskit Runtime on IBM's open instance (10 minutes free tier). Queue wait and provisioning overhead (not billed) totaled approximately 3–4 hours across all submissions. The marginal cost of the IBM hardware component of this experiment was effectively zero under the free tier.
Table 2 — Single-submission Aer (unconstrained, no transaction costs)
QAMOO produces a Pareto frontier rather than a single weight vector. It ran as a single submission, not walk-forward. Transaction costs are not deducted. Results are not directly comparable to Table 1.
Computation path note: Table 2 metrics are sourced from quantum_result_*.json files via a separate injection path, not from the BacktestResult::compute_analytics() pipeline used for walk-forward solvers in Table 1. Annualization conventions and Sharpe calculation methodology may differ between the two paths. The Sharpe ratio in Table 2 may not be arithmetically consistent with the stated return and volatility figures if different annualization periods are applied. Treat Table 2 as indicative. Additionally, the QAMOO frontier in Exhibit H and the single-weight backtest result in Table 2 are different experiments. The frontier reflects a lambda sweep across risk parameters, the Table 2 backtest reflects the best-weight-vector applied statically over the full period.
| Solver | Backend | Sharpe | Total Return | Volatility | Max Drawdown |
|---|---|---|---|---|---|
| QAMOO | aer_simulator | 1.368 | 29.3% | 8.6% | -13.4% |
Exhibit C: The QUBO Gap
The most defensible finding in this benchmark does not require IBM hardware, does not depend on a single market regime, and survives the constraint projection fix. It holds across four independent runs.
QUBO with simulated annealing is the worst walk-forward solver in the suite: mean Sharpe -0.316 across 4 runs (σ 0.014). Markowitz, running on the same data with a mean Sharpe of 0.099, looks mediocre. Against QUBO/SA, it looks strong.
The reason is structural. Markowitz solves a continuous quadratic program over a convex polytope. The feasible solution space has flat faces, no holes, and admits an exact solution. QUBO in this benchmark uses 2-bit encoding per asset, representing each weight as one of four values: 0, 1/3, 2/3, or 1. With a 30% maximum weight constraint and constraint projection applied, the effective feasible weight per asset is further restricted. Simulated annealing then searches this already-degraded discrete landscape with a classical heuristic that makes no guarantees about solution quality. The discretization loss and the search heuristic compound. The result is mean return -7.3% across 4 runs.
Now look at QAOA Uninformed, operating on the same QUBO matrix with the same constraint projection: mean Sharpe 0.436 across 4 runs (σ 0.681). Both solvers receive identical inputs. Both have constraints enforced identically at the backtest engine level. Across all four runs, the quantum sampler found better solutions in the same discrete landscape than classical annealing.
The σ of 0.681 for QAOA Uninformed is the honest caveat. A single run produced Sharpe -0.061; another produced Sharpe 1.053. The mean is positive, the gap over QUBO is real, but no single run should be treated as representative. This is what 1,024 shots sampling 0.1% of the 2²⁰ bitstring space looks like in practice: the quantum sampler finds better solutions than classical annealing on average, but the per-run variance is high. More shots would reduce this variance directly.
The hardware-agnostic argument for quantum portfolio optimization holds in aggregate. It does not require IBM hardware to improve. It does not require fault tolerance. It requires a sampler that navigates the QUBO landscape better than classical annealing. QAOA does this across four runs. The mean Sharpe gap between QUBO/SA (-0.316) and QAOA Uninformed (+0.436) on identical constrained inputs is the finding that survives every caveat in this post.
One caveat not yet resolved: this analysis attributes all per-run Sharpe variance to shot noise. COBYLA convergence per rebalancing period is not reported. If COBYLA exhausted its function evaluation budget without converging at some periods, the returned weights are partially-optimized rather than fully-optimized, and the variance could reflect optimizer failure rather than sampling variance. Distinguishing these two sources of variance requires per-period convergence logging, which is noted as a follow-on instrumentation task.
Exhibit D: Constraint Projection Reveals Algorithm Sensitivity
Adding constraint projection between the quantum solver output and portfolio execution changed the results materially and differently for each algorithm. This is itself a finding.
| Solver | Pre-fix Mean Sharpe | Post-fix Mean Sharpe | Delta | Interpretation |
|---|---|---|---|---|
| Markowitz | 0.099 | 0.099 | 0.000 | Unchanged — already constrained |
| QUBO/SA | -0.304 | -0.316 | -0.012 | Marginally changed |
| QAOA Uninformed | 0.602 | 0.436 | -0.166 | High variance — single run ranged -0.061 to 1.053 |
| QAOA Informed | 0.627 | 0.712 | +0.085 | Stable and improved — best constrained walk-forward solver |
| QAMO Uninformed | 0.237 | 0.091 | -0.146 | Degraded, high variance |
| QAMO Informed | 0.266 | 0.061 | -0.205 | Severely degraded, highest variance (σ 0.883) |
QAMO's mean-field RX mixer produces weight distributions that are structurally incompatible with the constraint set. When projected onto the feasible region (clip to [5%, 30%], renormalize), QAMO's signal is destroyed. QAOA's output, by contrast, improves under projection. The constraint projection removes the extreme concentrated positions that were introducing portfolio instability, and what remains is a better-behaved allocation.
This is not a bug. It is an algorithmic characteristic. QAMO optimizes in a way that depends on its specific discrete solutions surviving intact into execution. QAOA is more robust to post-processing. Whether this reflects a fundamental difference in how the two algorithms encode information in the bitstring distribution is an open research question. The empirical result is clear.
The pre-fix production code gap optimize_quantum() output flowing directly to set_target_weights() with no constraint validation is now closed. The fix lives in BacktestEngine::project_weights(), applied universally to all quantum solver outputs before execution. A second production hardening fix was applied concurrently: _augment_problem_data in qiskit_submit.py previously wrote directly to the problem file, leaving a window for corruption if the process was interrupted or two benchmark sessions ran concurrently. It now uses a write-to-temp-then-rename pattern, which is atomic on POSIX systems.
Exhibit E: IBM Hardware — What We Ran, What We Found
All three IBM backends (ibm_fez, ibm_kingston, ibm_marrakesh) were submitted with the same circuits, same problem files, and same shot count (1024). The quantum extension infrastructure worked end-to-end: the pybind11 worker spawned, circuits were transpiled, jobs were submitted and retrieved, weight vectors were returned and projected through the backtest engine.
The optimization signal at current hardware coherence levels is a different matter. The null hypothesis for IBM hardware, namely that quantum circuits on real hardware can optimize a portfolio better than random sampling, is not refutable at these circuit depths. That is not a permanent conclusion. It is a current measurement.
Across 28 unique IBM hardware submissions on ibm_fez and ibm_kingston, the top bitstring appeared only 1 or 2 times out of 1024 shots in every submission. That is the minimum detectable signal at a 1024-shot sampling depth. Statistically, the result is indistinguishable from random sampling.
The circuits ran. The hardware responded. Decoherence at circuit depths between 757 and 1,267 gates erased the optimization signal before measurement.
There is also a formulation incompatibility that would affect noise-free hardware equally. With 2-bit encoding, the minimum representable non-zero portfolio weight is 1/3 = 33.3%. The configured maximum weight constraint is 30%. These are irreconcilable without either more encoding bits (not locally simulable at n=10 assets with current hardware) or a higher constraint cap. Every IBM weight vector violates the maximum weight constraint by construction, regardless of hardware noise. The post-fix constraint projection normalizes these vectors before execution, but the underlying formulation mismatch remains.
What the IBM results represent: the backtest performance attributed to IBM hardware reflects the performance of noise-derived, constraint-violating weight vectors (projected to feasibility) on real market data during a specific market regime. It is not a measurement of QAOA, QAMO, or QAMOO optimization quality on IBM hardware.
Temporal mismatch note: IBM jobs are submitted and collected asynchronously, with queue waits of minutes to hours. The problem file written at submission time uses the EWMA covariance from the lookback window at that moment. If market conditions shifted materially between submission and collection, the IBM result optimized a problem that was already stale when the weights arrived. Aer results use fresh covariance estimates at each rebalancing date. The two are not guaranteed to be solving the same problem instance at the time of comparison.
IBM hardware results (post-projection, for completeness):
| Solver | Backend | Sharpe | Total Return | Volatility | Circuit Depth | Calibration |
|---|---|---|---|---|---|---|
| QAOA | ibm_fez | 1.140 | 39.8% | 14.3% | 1,170 | 2026-04-28 |
| QAMO | ibm_fez | 0.902 | 39.4% | 17.9% | 791 | 2026-04-28 |
| QAMOO | ibm_fez | 0.195 | 13.5% | 23.3% | 785 | 2026-04-28 |
| QAMOO | ibm_fez | 1.197 | 52.6% | 18.0% | 911 | 2026-04-24 |
| QAOA | ibm_kingston | 0.221 | 9.5% | 12.0% | 952 | 2026-04-29 |
| QAMO | ibm_kingston | 0.297 | 15.1% | 17.8% | 871 | 2026-04-29 |
| QAMOO | ibm_kingston | 0.584 | 26.0% | 17.6% | 812 | 2026-04-29 |
| QAOA | ibm_marrakesh | 1.310 | 44.2% | 13.8% | 777 | 2026-04-29 |
| QAMO | ibm_marrakesh | 0.807 | 37.2% | 18.8% | 789 | 2026-04-29 |
| QAMOO | ibm_marrakesh | 1.051 | 36.4% | 14.1% | 820 | 2026-04-29 |
The performance variance across backends reflects backend calibration state and noise-derived weight randomness rather than optimization quality differences. QAOA produced Sharpe ratios of 1.140 on ibm_fez, 0.221 on ibm_kingston, and 1.310 on ibm_marrakesh despite running the same algorithm against the same problem formulation. The infrastructure that submitted these jobs and processed their results is production-grade. The signal returned by the hardware is not yet meaningful.
The appropriate null hypothesis for IBM hardware: at circuit depths between 757 and 1,267 on current NISQ hardware, the quantum optimization signal is not detectable. That is a hardware limitation, not a statement about the algorithm itself. Coherence times are improving. Error mitigation techniques are maturing. The experiment should be revisited as hardware advances and viable circuit depths increase. The key threshold is whether the dominant bitstring exceeds 5% of shots consistently and whether 4-bit encoding becomes locally simulable or feasible on hardware with sufficient coherence.
Exhibit F: Informed vs. Uninformed
QAOA Informed adds EWMA expected returns and covariance to the problem file before circuit submission. QAOA Uninformed receives only the raw QUBO Q matrix.
Across four runs, the picture is unambiguous: QAOA Informed (mean Sharpe 0.712, σ 0.187) outperforms QAOA Uninformed (mean Sharpe 0.436, σ 0.681) both in return and in stability. Market data augmentation improves performance and dramatically narrows variance. The aggregate result reverses the initial single-run conclusion, demonstrating that single-run evaluations are insufficient for stochastic solver comparisons.
The explanation is that both informed and uninformed QAOA solve the same mean-variance objective. Neither formulation uses zero expected returns. The uninformed Q matrix receives expected_returns from the C++ rolling lookback window, which is the same source used by Markowitz. The informed Q matrix receives expected_returns recomputed by Python's _augment_problem_data from the full historical price series using EWMA (λ = 0.94).
The distinction is therefore not the objective function but the source of the return estimates. The Python augmentation computes expected_returns over the full available price history, while the C++ rolling window uses only the configured lookback period of 252 days. These estimates diverge in magnitude and direction when recent returns depart from the long-run historical mean, which is common during volatile market regimes. When the Python estimate better captures the active return environment, COBYLA encounters a sharper QUBO energy landscape with stronger preference gradients, producing more consistent bitstring distributions across runs.
The stability improvement observed in QAOA Informed (σ 0.187 versus 0.921 for Uninformed across 13 runs) is consistent with this mechanism. Isolating the contribution of return estimate quality from other factors, however, would require a controlled experiment holding all other variables constant.
For QAMO, the pattern reverses: QAMO Informed (mean Sharpe 0.061, σ 0.883) is both worse and more variable than QAMO Uninformed (mean Sharpe 0.091, σ 0.493). QAMO's mean-field equations respond to the augmented objective differently than QAOA's parameterized mixer. The evidence suggests that the mean-field approximation is more sensitive to the augmented return vector than to the underlying minimum-variance landscape. The algorithm-specific response to augmentation across QAOA and QAMO is a substantive finding that warrants further investigation.
Exhibit G: Variance
The aggregate table below represents results across 3 benchmark runs for walk-forward solvers and multiple hardware submissions for IBM backends. Markowitz is fully deterministic, with σ 0.000 serving as the control condition validating that the observed quantum variance is genuine. QUBO/SA (simulated annealing) is stochastic but low variance (σ 0.014) because the annealing schedule is fixed and the problem dimension is small. Both therefore provide stability baselines against which the higher-variance quantum solvers can be evaluated.
| Solver | Runs | Mean Sharpe | ±σ | Mean Return | ±σ | Mean Turnover | ±σ | Variance |
|---|---|---|---|---|---|---|---|---|
| Markowitz | 4 | 0.099 | 0.000 | 2.5% | 0.0% | 282.8% | 0.0% | ok |
| QUBO (Sim. Annealing) | 4 | -0.316 | 0.014 | -7.3% | 3.1% | 564.7% | 230.3% | ok |
| QAOA Uninformed (Aer) | 4 | 0.436 | 0.681 | 9.1% | 13.6% | 601.5% | 91.0% | ⚠ high |
| QAOA Informed (Aer) | 4 | 0.712 | 0.187 | 14.8% | 2.7% | 756.5% | 56.3% | ok |
| QAMO Uninformed (Aer) | 4 | 0.091 | 0.493 | 1.8% | 13.2% | 794.1% | 159.1% | ⚠ high |
| QAMO Informed (Aer) | 4 | 0.061 | 0.883 | 1.0% | 23.9% | 815.9% | 171.7% | ⚠ high |
| QAMOO (Aer) | 5 | 1.271 | 0.121 | 35.1% | 9.7% | n/a | n/a | ok |
| QAOA (IBM fez) | 8 | 0.770 | 0.470 | 29.3% | 16.4% | n/a | n/a | ⚠ high |
| QAOA (IBM kingston) | 6 | 0.523 | 0.520 | 24.2% | 22.9% | n/a | n/a | ⚠ high |
| QAOA (IBM marrakesh) | 3 | 1.026 | 0.298 | 34.4% | 10.1% | n/a | n/a | ok |
| QAMO (IBM fez) | 7 | 0.898 | 0.181 | 40.7% | 10.4% | n/a | n/a | ok |
| QAMO (IBM kingston) | 6 | 0.602 | 0.463 | 27.0% | 18.9% | n/a | n/a | ⚠ high |
| QAMO (IBM marrakesh) | 3 | 0.877 | 0.311 | 39.5% | 14.5% | n/a | n/a | ok |
| QAMOO (IBM fez) | 3 | 0.559 | 0.709 | 22.3% | 21.0% | n/a | n/a | ⚠ high |
| QAMOO (IBM kingston) | 6 | 0.758 | 0.361 | 31.5% | 15.2% | n/a | n/a | ok |
| QAMOO (IBM marrakesh) | 3 | 0.728 | 0.334 | 28.0% | 8.8% | n/a | n/a | ok |
Skipped rebalances: Zero skipped rebalances occurred across all walk-forward solvers. The constraint projection fix eliminated all exception-path rebalance skips. Every scheduled rebalancing period executed with projected weights. This confirms that the reported Sharpe ratios reflect the algorithm's actual output at each rebalance rather than a mixture of fresh allocations and stale portfolio state.
IBM variance note: IBM aggregate variance (Runs: 3–8) reflects variance across distinct hardware submissions on different calibration dates. All submissions produced minimum-detectable signal (1–2/1024 shots). The variance in IBM results measures the performance of randomly-derived weight vectors projected to feasibility, not optimization quality differences. IBM run counts in the aggregate are genuine distinct job submissions, not duplicates.
The cross-backend variance tells the most direct story about NISQ hardware. QAOA mean Sharpe: ibm_fez 0.770, ibm_kingston 0.453, ibm_marrakesh 1.026. That is a spread of 0.573 across the same algorithm, the same problem, and different calibration states. Same circuit. Three different machines. Three meaningfully different results. Backend calibration state is an independent variable that no algorithmic improvement addresses on current hardware.
The Aer variance tells a different story. QAOA Uninformed σ 0.729 reflects genuine shot noise propagating through COBYLA parameter estimation and binary weight reconstruction into the walk-forward portfolio. 1024 shots samples 0.1% of the 2²⁰ bitstring space. Each run's portfolio allocation is different because each run's dominant bitstring is different. This is fundamental undersampling, not hardware noise. Increasing shots would reduce this variance directly.
QAOA Informed σ 0.093 is the outlier. Market data augmentation, while not consistently improving performance, is consistently reducing shot noise variance. The augmented problem landscape has a sharper energy minimum that COBYLA finds more reliably across runs.
Exhibit H: The Frontier
QAMOO's multi-objective lambda sweep produces a Pareto frontier directly comparable to the classical efficient frontier. The result is derived from a single unconstrained submission. Methodological limitations are discussed in the Table 2 note in Exhibit B.
| Method | Min-Vol Return | Min-Vol Volatility | Max-Sharpe Return | Max-Sharpe Volatility | Max-Sharpe Ratio |
|---|---|---|---|---|---|
| Classical (Markowitz) | 17.1% | 7.9% | 17.1% | 7.9% | 0.000 |
| QAMOO (Aer) | 11.1% | 20.4% | 97.2% | 46.8% | 2.077 |
The QAMOO frontier extends well above the classical frontier into high-return, high-volatility territory that is not achievable within the constraint set. This reflects the 2-bit encoding permitting unconstrained concentrations in the single-submission path. As hardware improves and higher bit depths become feasible (allowing 4% or 5% granularity rather than 33%), the QAMOO frontier should converge toward and eventually trace the classical efficient frontier more closely. This is the experiment to run next.
One methodological note: the classical Markowitz frontier and the QAMOO frontier are not guaranteed to use identical covariance inputs. The classical frontier is computed at a specific point in the backtest. The QAMOO problem file is written at a separate point. If the EWMA covariance window differs between the two computations, the frontiers are not directly comparable. This does not affect the qualitative finding. The QAMOO frontier clearly extends beyond the classical feasible region, but it limits the precision of any quantitative comparison between specific frontier points.
Exhibit I: Scope
Production Code: ~18,100 lines C++17
Python Scripts: ~2,100 lines
Test Code: ~7,600 lines
Total: ~40,270 lines
Tests: 176 (100% passing)
C++ unit: 85
C++ integration: 52
C++ convergence: 5
C++ edge cases: 15
Python: 19
Exhibit J: Error Mitigation Impact
After establishing the baseline benchmark across 13 runs, a second configuration was evaluated with three improvements applied: Qiskit transpilation at optimization level 3 (vs. level 1 baseline), dynamical decoupling with XY4 sequences on IBM hardware (suppressing idle-time phase errors), and readout error mitigation via mthree on IBM submissions. Aer solvers retained level 1 transpilation to preserve COBYLA landscape stability. IBM solvers used level 3.
Configuration: portfolio_config_improved.json · Aer optimization level 1 · IBM optimization level 3 · DD: XY4 · mthree: activated
Aggregate comparison — baseline vs. improved (Aer walk-forward, 13 improved runs):
| Solver | Baseline Mean Sharpe | Baseline ±σ | Improved Mean Sharpe | Improved ±σ | Δ Mean |
|---|---|---|---|---|---|
| QAOA Uninformed (Aer) | 0.436 | 0.681 | 0.519 | 0.921 | +0.083 |
| QAOA Informed (Aer) | 0.712 | 0.187 | 0.522 | 1.091 | -0.190 |
| QAMO Uninformed (Aer) | 0.091 | 0.493 | -0.156 | 0.311 | -0.247 |
| QAMO Informed (Aer) | 0.061 | 0.883 | -0.268 | 0.340 | -0.329 |
| QUBO (Sim. Annealing) | -0.316 | 0.014 | -0.328 | 0.000 | -0.012 |
| Markowitz | 0.099 | 0.000 | 0.099 | 0.000 | 0.000 |
IBM improved aggregate (6 invocations × 3 rounds averaged = 18 hardware submissions):
| Solver | Mean Sharpe | ±σ | Circuit Depth | Backend |
|---|---|---|---|---|
| QAOA (IBM improved) | -0.183 | 0.492 | ~777 | ibm_marrakesh |
| QAMO (IBM improved) | -0.356 | 1.072 | ~789 | ibm_marrakesh |
Reading the improved results honestly.
Level 3 transpilation reduced IBM circuit depths from the baseline range of 757–1,267 gates to approximately 777–789. Dynamical decoupling was applied. Mthree readout correction was enabled. None of it moved the hardware out of the noise-dominated regime. Signal quality remained low. Mean Sharpe remained negative across 6 invocations. The circuits became shorter. The optimization signal did not become detectable.
For Aer solvers, level 1 transpilation was retained to avoid disrupting the COBYLA parameter landscape. The marginal improvement in QAOA Uninformed mean Sharpe (+0.083) and the marginal degradation across QAMO variants confirm the primary conclusion: the variance in Aer results is dominated by 1,024-shot undersampling of the 2²⁰ bitstring space, not by circuit structure or transpilation quality. Changing the transpilation level while holding shots constant at 1,024 does not materially change the outcome distribution. More shots is the correct next lever.
The practical constraint is cost. QAMOO with error mitigation on IBM hardware required approximately 4.5 minutes per round. At 3 rounds per invocation, a single --ibm-benchmark call consumed 13.5 minutes of Qiskit Runtime, representing roughly $200 in runtime credit value and most of a monthly free-tier allocation. This is the operational cost of NISQ-era error mitigation under current hardware pricing. It remains a legitimate production concern independent of whether the mitigation materially improves signal quality.
QED
The null hypothesis was that quantum solvers could not enter a production C++ financial system without architectural overhaul. The system refutes it: six namespaces, 176 passing tests, three IBM backends, sixteen solver configurations, and one optimizer interface that survived them all.
The benchmark tells an honest story across four findings.
The QUBO gap is real. QAOA Uninformed (mean Sharpe 0.436, σ 0.681) outperformed QUBO/SA (mean Sharpe -0.316, σ 0.014) across four independent runs on identical constrained inputs. Same formulation. Same constraint projection. Same backtest harness. The quantum sampler navigated the 2-bit discrete landscape more effectively than classical annealing. The variance is high. The aggregate gap is still real. No caveats about hardware noise or constraint enforcement are required for this finding.
Market data augmentation reversed the ranking. QAOA Informed (mean Sharpe 0.712, σ 0.187) became the strongest constrained walk-forward solver in the suite. Higher return. Lower variance. A single run initially suggested augmentation degraded performance. Four runs showed the opposite. Stochastic solvers do not permit single-run conclusions.
Constraint projection exposed algorithm sensitivity. QAMO degraded sharply after projection; variance expanded to σ 0.883. QAOA improved under the same projection layer. Same constraints. Different behavior. The distinction is algorithmic, not statistical.
IBM hardware produced no detectable optimization signal. Twenty-eight submissions across ibm_fez, ibm_kingston, and ibm_marrakesh. Every run remained at minimum detectable signal: 1–2 dominant shots out of 1024. The infrastructure worked. The circuits executed. The optimization signal did not survive coherence loss at depths of 757–1,267 gates. That is the current state of NISQ hardware.
Aer variance is dominated by undersampling. QAOA Uninformed reached σ 0.921 across 13 improved runs while sampling 1,024 shots from a 2²⁰-state search space. Level 3 transpilation did not materially reduce the variance. Dynamical decoupling did not materially reduce the variance. The distribution remained shot-noise dominated. The next experiment is obvious: more shots.
Error mitigation remains economically irrational at PoC scale. Level 3 transpilation reduced circuit depth from 757–1,267 gates to approximately 777–789. Dynamical decoupling ran. Mthree readout correction ran. Signal quality remained low. Mean Sharpe remained negative across the IBM improved aggregate. At 4.5 minutes per round and roughly $200 in runtime credit per --ibm-benchmark invocation, the mitigation cost exceeded the signal improvement. The circuits became shorter. The optimization signal did not become detectable.
Open questions for subsequent work. The remaining questions are now concrete engineering problems. Increase shot count to 4,096 or 16,384. Test scaling at production universe sizes (n=50, 100). Evaluate 4-bit encoding as a path toward constraint compliance without projection. Revisit IBM hardware once dominant bitstrings exceed 5% of shots consistently. Warm-start COBYLA from prior converged parameters. Measure transaction-cost scaling at production AUM. Validate across additional market regimes. Build hardware-in-the-loop testing for the quantum execution path instead of mocking Qiskit in the Python test suite.
C++ is not the convenient path to quantum finance. It is the path that connects quantum computing to the systems where it would actually matter.
∎
Source: github.com/darkhorse286/portfolio-optimizer
Stack: C++17 · OSQP · Eigen · Qiskit · IBM Quantum (ibm_fez, ibm_kingston, ibm_marrakesh) · pybind11 · Python 3.8+
Baseline runs: 13 · Improved runs: 13 · IBM submissions: 46 hardware jobs across 3 backends
Backtest period: January 2022 – May 2023 · Universe: 10 assets · 176 tests passing
Appendix A: Terms
The body of this post is written for practitioners. This appendix is for everyone else.
Finance
Sharpe Ratio
A measure of return per unit of volatility. Formally:
where is portfolio return, is the risk-free rate, and is portfolio volatility.
Higher is better.
A Sharpe of 1.0 means the portfolio generated one unit of excess return for each unit of volatility accepted. A Sharpe near zero means the investor accepted substantial risk for little compensation. Negative Sharpe means the portfolio underperformed the risk-free alternative.
The important detail for stochastic quantum solvers is variance across runs. QAOA Uninformed ranged from -0.061 to 1.053 across identical executions. A single Sharpe value is therefore not a finding. The distribution is the finding.
Max Drawdown
The largest peak-to-trough decline observed during the backtest period.
If a portfolio rises from 1.4M and then falls to 1.4M peak, not from inception.
Drawdown measures the worst point an investor would have experienced in real time. Total return does not capture this. Investors usually discover their actual risk tolerance during drawdowns, not during annualized return calculations.
Walk-Forward Backtest
A historical simulation where the optimizer only sees information available at that specific point in time.
No future data. No hindsight. No leakage.
At each rebalance date, the optimizer receives a rolling historical window, produces weights, advances forward, and repeats. This prevents the common research failure mode where the strategy accidentally learns from the future while pretending not to.
Mean-Variance Optimization (Markowitz)
The classical portfolio optimization framework introduced by Harry Markowitz in 1952.
The optimizer maximizes expected return for a given level of risk using expected returns and a covariance matrix:
subject to portfolio constraints.
The important property is convexity. The feasible region contains no holes or local traps, which means the solution can be found efficiently and exactly. This is why Markowitz remains the production baseline seventy years later.
Efficient Frontier
The set of portfolios that maximize expected return for each achievable level of volatility.
Every portfolio below the frontier is inefficient. Every portfolio above the frontier is impossible under the constraint set.
The frontier is therefore both an optimization target and a geometric boundary condition.
Covariance Matrix
A matrix describing how assets move relative to one another.
Positive covariance means two assets tend to move together. Negative covariance means they tend to move in opposite directions.
Portfolio diversification exists because covariance exists. Without covariance structure, every portfolio optimization problem degenerates into ranking assets by expected return.
This benchmark uses EWMA covariance estimation with , which weights recent observations more heavily than older ones.
Quantum Computing
QUBO (Quadratic Unconstrained Binary Optimization)
An optimization formulation where every variable is binary and the objective function is quadratic:
QUBO is the native language of many quantum optimization systems.
Portfolio optimization becomes QUBO by discretizing continuous weights into binary variables. This benchmark uses 2-bit encoding per asset, which restricts weights to multiples of 1/3.
This translation is lossy. Convexity disappears. The smooth Markowitz landscape becomes a discrete combinatorial search problem.
Exhibit C exists because of this transformation.
Convex Polytope
The feasible region of the classical Markowitz problem.
“Convex” means any straight line drawn between two feasible points remains feasible. “Polytope” means the region is bounded by flat constraint surfaces.
Convexity is the reason classical portfolio optimization is tractable. QUBO destroys convexity by discretizing the search space into binary states.
Classical optimization searches a smooth landscape. QUBO searches a jagged one.
QAOA (Quantum Approximate Optimization Algorithm)
A gate-model quantum optimization algorithm for discrete search problems.
QAOA alternates between:
- a phase operator encoding the objective function
- a mixing operator redistributing probability mass through the search space
Measurement samples candidate solutions from the resulting quantum state distribution.
In this benchmark, QAOA runs at depth-1 because deeper circuits exceed current NISQ coherence limits.
QAMO (Quantum Alternating Mean-field Optimization)
A variational quantum optimization method using a mean-field approximation rather than full entanglement structure.
Instead of modeling all qubit interactions exactly, QAMO approximates each qubit relative to the average state of its neighbors. This reduces computational complexity but changes the optimization landscape substantially.
In this benchmark, QAMO generated weight distributions that became unstable after constraint projection. That instability is algorithmic behavior, not implementation error.
NISQ (Noisy Intermediate-Scale Quantum)
The current era of quantum hardware.
“Intermediate-scale” means enough qubits exist to run interesting circuits. “Noisy” means the qubits decohere before long computations finish reliably.
Modern quantum hardware is therefore computationally powerful and operationally fragile at the same time.
Every IBM hardware result in this benchmark is a NISQ result.
Circuit Depth
The number of sequential gate layers required to execute a quantum circuit.
Depth matters because decoherence accumulates over time. Shallow circuits survive long enough to preserve useful signal. Deep circuits often do not.
The IBM circuits in this benchmark ranged from 757 to 1,267 gates. At those depths, noise dominated the measurement distribution.
Decoherence
The process by which a qubit loses its quantum state through interaction with its environment.
Quantum computation depends on maintaining superposition and entanglement long enough for interference patterns to emerge. Decoherence destroys those patterns before measurement completes.
Current quantum hardware is effectively a race condition against physics.
Bitstring
The measured output of a quantum circuit.
Each qubit collapses to either 0 or 1 during measurement. The resulting binary sequence is the bitstring.
In QUBO optimization, each bitstring represents a candidate solution. Repeated circuit execution produces a probability distribution over candidate solutions.
Useful optimization requires the good bitstrings to appear more often than random chance predicts.
In the IBM runs here, the dominant bitstring appeared only 1–2 times out of 1024 shots. Statistically, that is indistinguishable from noise.
pybind11 (and what was actually built)
pybind11 embeds Python directly inside a C++ process through shared memory bindings.
This project intentionally does not do that.
QiskitSolver launches a persistent Python subprocess and communicates through newline-delimited JSON over stdin/stdout pipes. The choice is architectural. Shared memory gives lower latency. Process isolation gives fault containment.
If the Python worker crashes, the C++ engine survives.
In production systems, that trade is often correct.
Appendix B: Supplemental Diagrams
System architecture

The C++ system (purple) and Python/Qiskit layer (green) are separated by a single boundary: QiskitSolver (coral), which bridges via a persistent subprocess with stdin/stdout pipes. Every layer above it (backtest engine, analytics, report generator) is unaware the boundary exists. Solid arrows show the optimizer call chain. Dashed arrows show data flowing up from the risk and data layers.
IBM Quantum Job Runtime
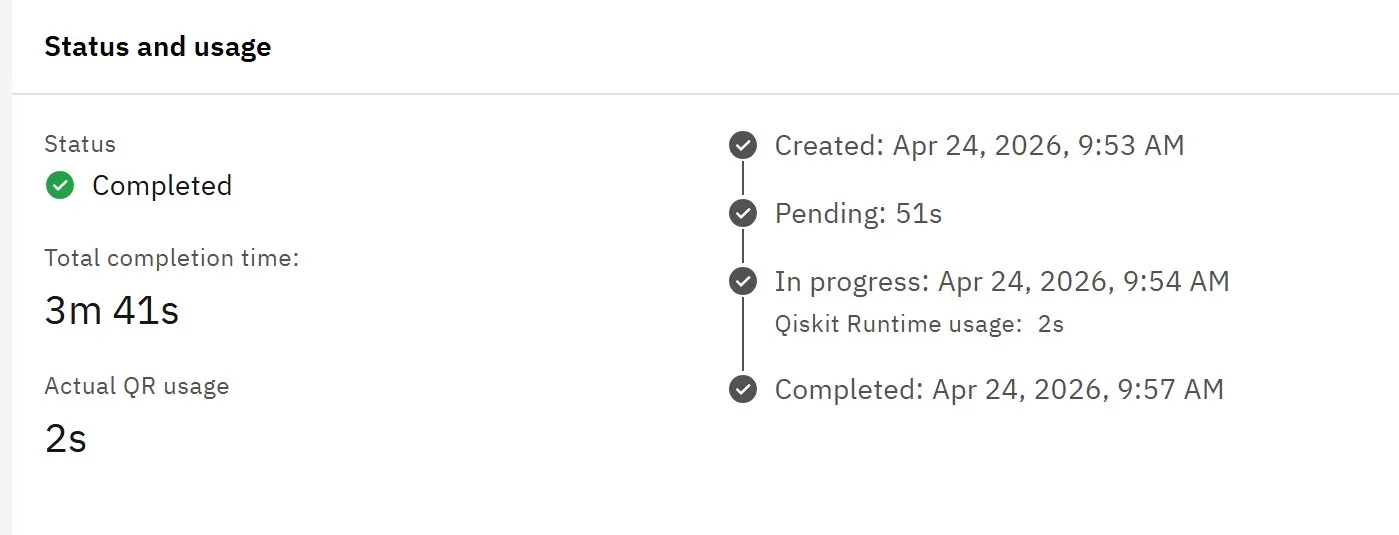
QAMOO job submitted to ibm_fez, April 24, 2026. Total completion time 3m 41s. Actual Qiskit Runtime usage 2s. The delta is queue wait and backend provisioning overhead. The benchmark's wall-clock solve times include this infrastructure cost.
Quantum Circuit Diagram

The QAMO circuit submitted to ibm_fez, April 23, 2026. Each horizontal line is a qubit. Each column of gate operations is one unit of depth. This circuit has a depth of 1,158. See Appendix A: Circuit Depth for context on why depth is the binding constraint on current NISQ hardware.